Towards Robust Mathematical Reasoning
Thang Luong◊(lead), Dawsen Hwang*, Hoang Nguyen*† Golnaz Ghiasi*, Yuri Chervonyi*, Insuk Seo*, Junsu Kim*, Garrett Bingham, Jonathan Lee, Swaroop Mishra†, Alex Zhai, Clara Huiyi Hu, Henryk Michalewski, Jimin Kim†, Jeonghyun Ahn†, Junhwi Bae†, Xingyou Song, Trieu H. Trinh, Quoc V. Le, Junehyuk Jung◊
*Core and equal contributors † Work previously conducted under Google DeepMind.
Introduction
In July 2025, we celebrated a historic achievement: our advanced Gemini model with Deep Think technology reached a gold-medal standard at the International Mathematical Olympiad (IMO). This was a landmark moment for AI. But the win wasn't just about getting strong performances at IMO problems - it was about building a system capable of deep, robust mathematical reasoning.
At EMNLP 2025, we are excited to introduce IMO-Bench, a suite of advanced reasoning benchmarks that played a crucial role in our IMO-gold journey and were designed to push the frontiers of mathematical reasoning in AI. Vetted by a panel of IMO medalists and mathematicians (together, they won 10 gold and 5 silver IMO medals), IMO-Bench specifically targets the level of IMO due to its notoriously difficult problems, which require both rigorous multi-step reasoning and creativity beyond simple application of known formulas. We release IMO-Bench together with rich grading data to the community to help enable further advancements towards robust mathematical reasoning.
“IMO-Bench is an impressive collection of high quality data for AI evaluation covering a diverse and representative set of topics and difficulties in high school level math competitions. I am very pleased to see this benchmark being used in developing an AI that achieved gold medal standard this year.”
Yufei Zhao (IMO Gold Medalist, 3-time Putnam Fellow, and Professor of Mathematics, MIT).
IMO-Bench at a glance
IMO-Bench consists of three benchmarks that judge models on diverse capabilities: IMO-AnswerBench - a large-scale test on getting the right answer, IMO-ProofBench - a next-level evaluation for proof writing, and IMO-GradingBench to enable further progress in automatic evaluation of long-form answers.
| Benchmark | Size | Task |
|---|---|---|
| IMO-AnswerBench | 400 | Get the right answer |
| IMO-ProofBench | 60 | Write a rigorous proof |
| IMO-GradingBench | 1,000 | Grade a proof |
A key highlight of our work is to show that autograders built with Gemini reasoning correlate well with human evaluations on IMO-ProofBench, as illustrated below, for a wide range of foundation models. This was achieved thanks to the accompanying grading schemes in IMO-Bench, which are suitable for both human experts and automated systems. We ultimately hope to steer the community's focus from final answers to the proofs themselves, enabling a more rigorous assessment of AI reasoning processes.
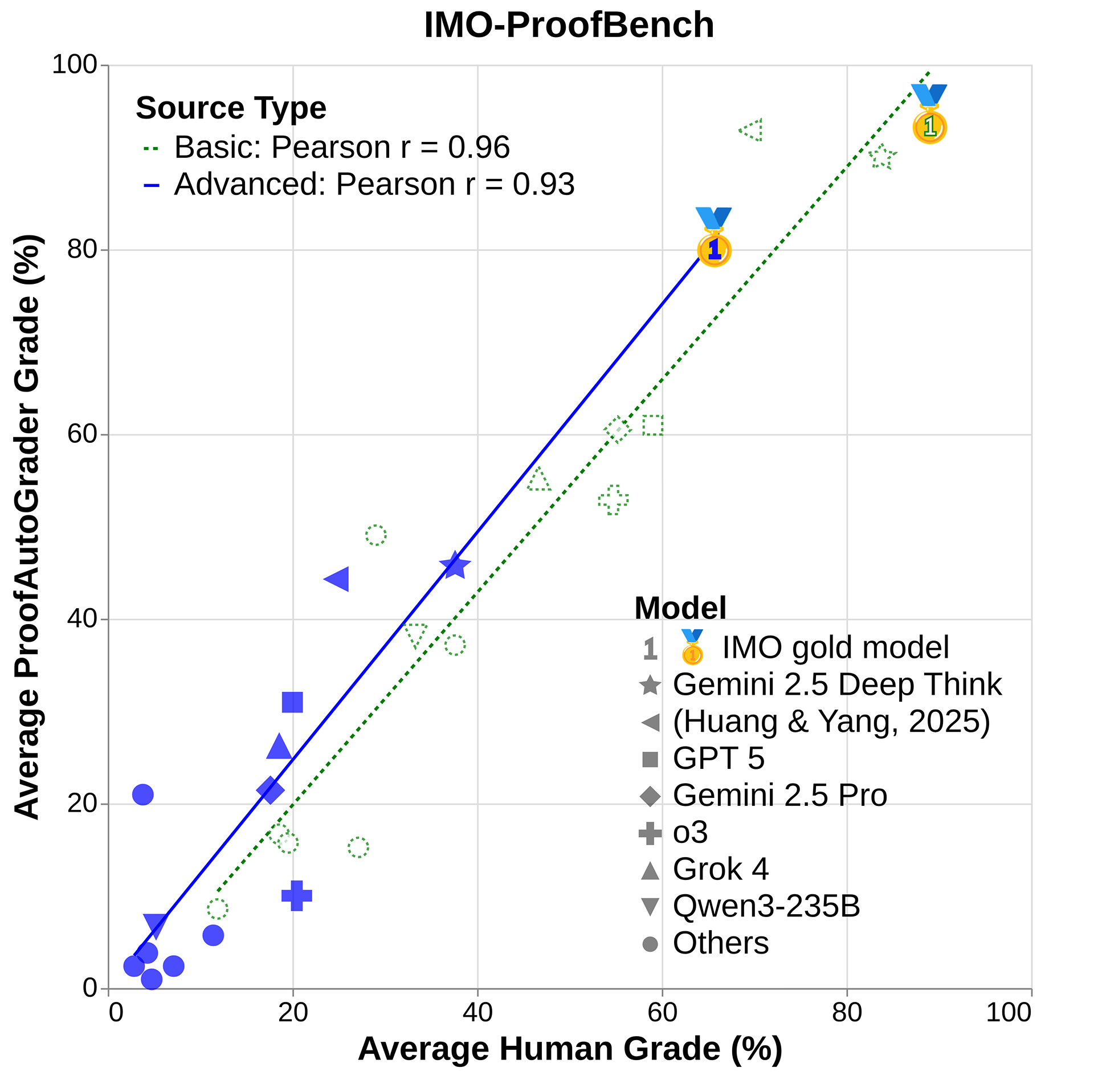
IMO-ProofBench, a key benchmark in IMO-Bench, for measuring proof-writing capabilities. We demonstrated high correlations between human and automatic evaluations on a variety of public models, including our IMO-gold model (Luong and Lockhart, 2025).
Beyond Short Answers with IMO-ProofBench
While the final answer accuracy offers a valuable metric for measuring mathematical abilities, it is insufficient for a comprehensive assessment of mathematical reasoning. We, hence, introduce IMO-ProofBench as the next-level evaluation designed to evaluate the ability of AI models in constructing rigorous and valid mathematical arguments. With 60 proof-based problems, the benchmark is divided into two subsets: a basic set covering pre-IMO to IMO-Medium difficulty levels, and an advanced set featuring novel, highly challenging problems simulating complete IMO examinations, up to IMO-Hard level. Our goal for the basic set is to assess models in their early stages of development. Sufficiently strong performance on the basic set would justify progression to the advanced set.
Performances on the basic IMO-ProofBench varies significantly: while Gemini Deep Think (IMO Gold) achieves a high score of 89.0%, most models score below 60%, indicating that there is still considerable room for improvements. The advanced IMO-ProofBench proves to be a more significant challenge that all non-Gemini models score below 25%. Our IMO-gold model achieved a state-of-the art score of 65.7% according to human evaluations. This represents a substantial leap in capability, but its distance from a perfect score indicates that even the strongest models have room for growth in sophisticated mathematical reasoning.
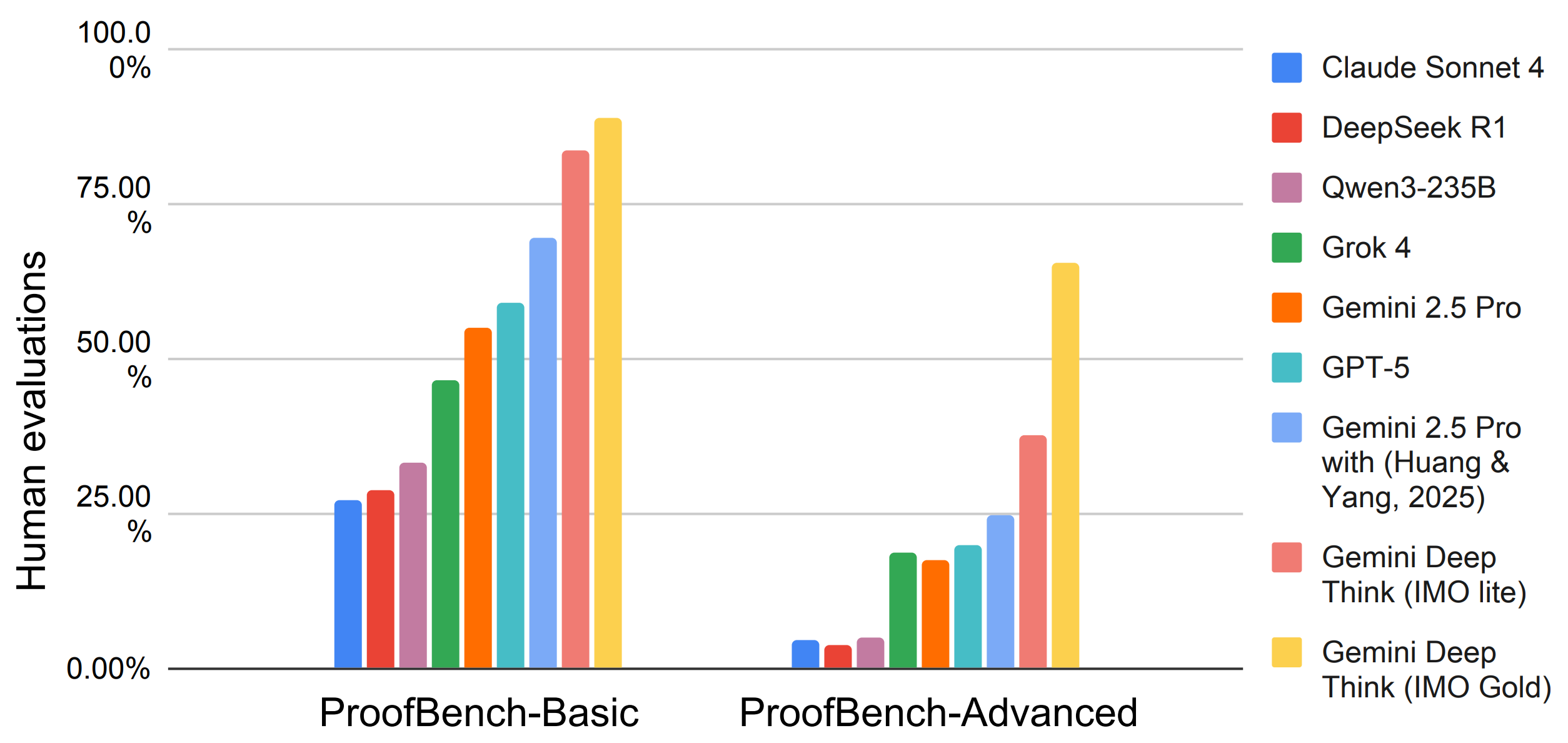
Expert evaluation results on the Basic and Advanced subsets of IMO-ProofBench. Scores are presented as a percentage of the total possible points, with each problem graded from 0-7.
Proof Autograder
While human expert evaluation remains the gold standard for mathematical proofs, its cost and time intensity limit scalable research. To address this, we built ProofAutoGrader, an automatic grader for IMO-ProofBench. The autograder leverages Gemini 2.5 Pro, providing it with a prompt containing the problem statement, the candidate solution, a reference solution, and specific grading guidelines.
When applying ProofAutoGrader to the 14 public models on IMO-ProofBench, the average grades from our automatic grader strongly correlate with human grades, yielding high Pearson correlation coefficients of 0.96 and 0.93 on both basic and advanced problems respectively. In addition, we also tested ProofAutoGrader on 170 internal systems, developed as part of our IMO effort. On this larger pool, the automatic grader achieved a lower, but still reasonable Pearson correlation coefficient of 0.87.
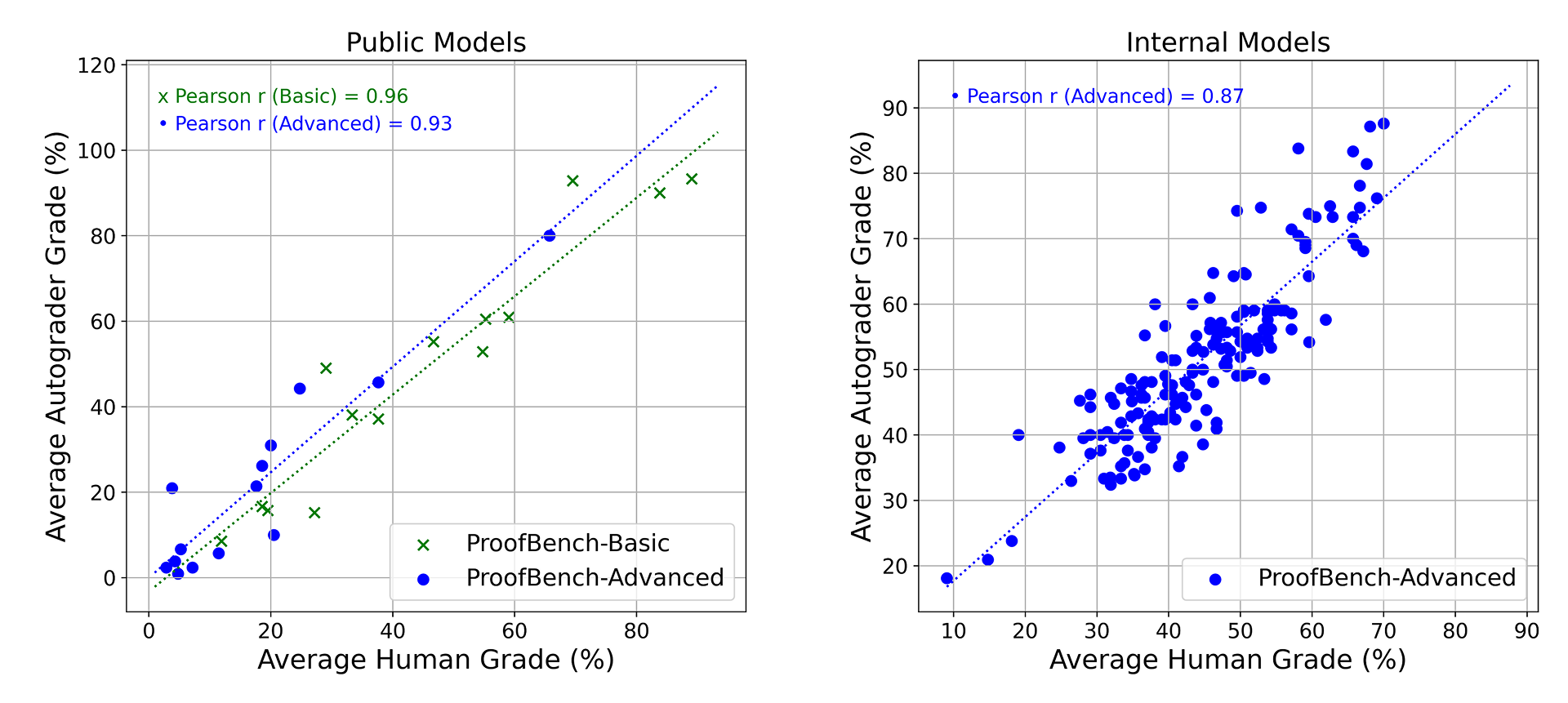
Correlation between ProofAutoGrader and human experts on IMO-Proof Bench, evaluated over 14 public models (left) and 170 internal models during our IMO-gold journey (right).
Leaderboard
Here, we show a leaderboard of 19 systems on the advanced IMO-ProofBench.
| Model | Advanced ProofBench | Breakdown | Query date | ||
|---|---|---|---|---|---|
| Novel | IMO 2024† | USAMO 2025 | |||
| Gemini Deep Think (IMO Gold) | 65.7% | 61.1% | 76.2% | 69.0% | 2025-08-02 |
| Gemini Deep Think (IMO lite) | 37.6% | 31.7% | 40.5% | 52.4% | 2025-08-20 |
| GPT-5 Pro | 28.6% | 29.4% | 19.0% | 35.7% | 2025-11-26 |
| Gemini 2.5 Pro with (Huang & Yang, 2025) | 24.8% | 17.5% | 19.1% | 52.4% | 2025-07-14 |
| Grok 4 (heavy) | 23.3% | 11.1% | 7.1% | 76.2% | 2025-07-12 |
| o3 | 20.5% | 15.1% | 4.8% | 52.4% | 2025-08-04 |
| GPT-5 | 20% | 15.9% | 33.3% | 19.0% | 2025-09-18 |
| Gemini 3 Pro Preview | 18.6% | 17.3% | 8.9% | 32.1% | 2025-11-24 |
| Grok 4.1 Fast Reasoning | 18.6% | 19.8% | 16.7% | 16.7% | 2025-11-26 |
| Grok 4 | 18.6% | 17.5% | 16.7% | 23.8% | 2025-08-20 |
| Gemini 2.5 Pro | 17.6% | 15.9% | 7.1% | 33.3% | 2025-08-04 |
| o4-mini (high reasoning) | 11.4% | 8.7% | 7.1% | 23.8% | 2025-08-04 |
| GPT-5.1 | 7.1% | 1.6% | 14.3% | 16.7% | 2025-11-26 |
| Kimi-K2-Instruct | 7.1% | 4% | 2.4% | 21.4% | 2025-08-21 |
| Qwen3-235B | 5.2% | 7.1% | 0.0% | 4.8% | 2025-08-21 |
| Claude Sonnet 4 | 4.8% | 6.4% | 2.4% | 2.4% | 2025-09-17 |
| DeepSeek V3 | 4.3% | 6.3% | 2.4% | 0.0% | 2025-09-16 |
| DeepSeek R1 | 3.8% | 6.4% | 0.0% | 0.0% | 2025-09-16 |
| Claude Opus 4 | 2.9% | 0.0% | 2.4% | 11.9% | 2025-08-04 |
Expert evaluation results on the Advanced subset of IMO-Proof Bench. Scores are presented as a percentage of the total possible points for the problems in each respective subset, with each problem graded from 0–7. The Advanced IMO-Proof Bench is further broken down by problem source. †Robustified IMO 2024 problem set.
A breakdown of the advanced IMO-Proof Bench reveals a significant performance disparity across problem types, suggesting potential overfitting in certain models. This trend is most evident with Grok 4 (heavy), which scores 76.2% on USAMO 2025 but only 11.1% on novel problems. Other models, including o3 (52.4% vs. 15.1%) and Gemini 2.5 Pro with (Huang & Yang, 2025) (52.4% vs. 17.5%), exhibit a similar, pronounced gap.
In contrast, Gemini Deep Think (IMO Gold) scored 69.0% on the USAMO and 61.1% on the novel sets, indicating it has more general capabilities without overfitting to a particular dataset. The low performances of latest frontier models such as GPT-5 Pro and Grok 4 (heavy) on the advanced IMO-Proof Bench underscore the difficulty of advanced mathematical reasoning and highlight the importance of rigorous examination of the full details of model outputs for a complete understanding of their mathematical abilities.
Other Benchmarks in IMO-Bench
IMO-AnswerBench
IMO-AnswerBench is a standard benchmark, consisting of 400 problems with verifiable answers carefully chosen from past Olympiad competitions. The problems span across four IMO categories (Algebra, Combinatorics, Geometry, and Number Theory) and are altered by experts to avoid memorization. For each category, the benchmark contains 100 problems across four levels of difficulty: pre-IMO (middle school or pre-Math Olympiad problems), IMO-Easy (equivalent to Problem 1 or Problem 4 at the IMO), IMO-Medium (equivalent to Problem 2 or Problem 5 at the IMO) and IMO-Hard (equivalent to Problem 3 or Problem 6 at the IMO or post-Math Olympiad problems).
| Category | Pre-IMO | IMO-Easy | IMO-Medium | IMO-Hard |
|---|---|---|---|---|
| Algebra | 11 | 46 | 32 | 11 |
| Combinatorics | 4 | 19 | 31 | 46 |
| Geometry | 13 | 44 | 32 | 11 |
| Number Theory | 2 | 20 | 31 | 47 |
Difficulty statistics for IMO-AnsBench.
Problems were chosen from a variety of topics whose solutions require different problem solving techniques to ensure a diverse representation of topics, ideas, and domain knowledge as illustrated below.
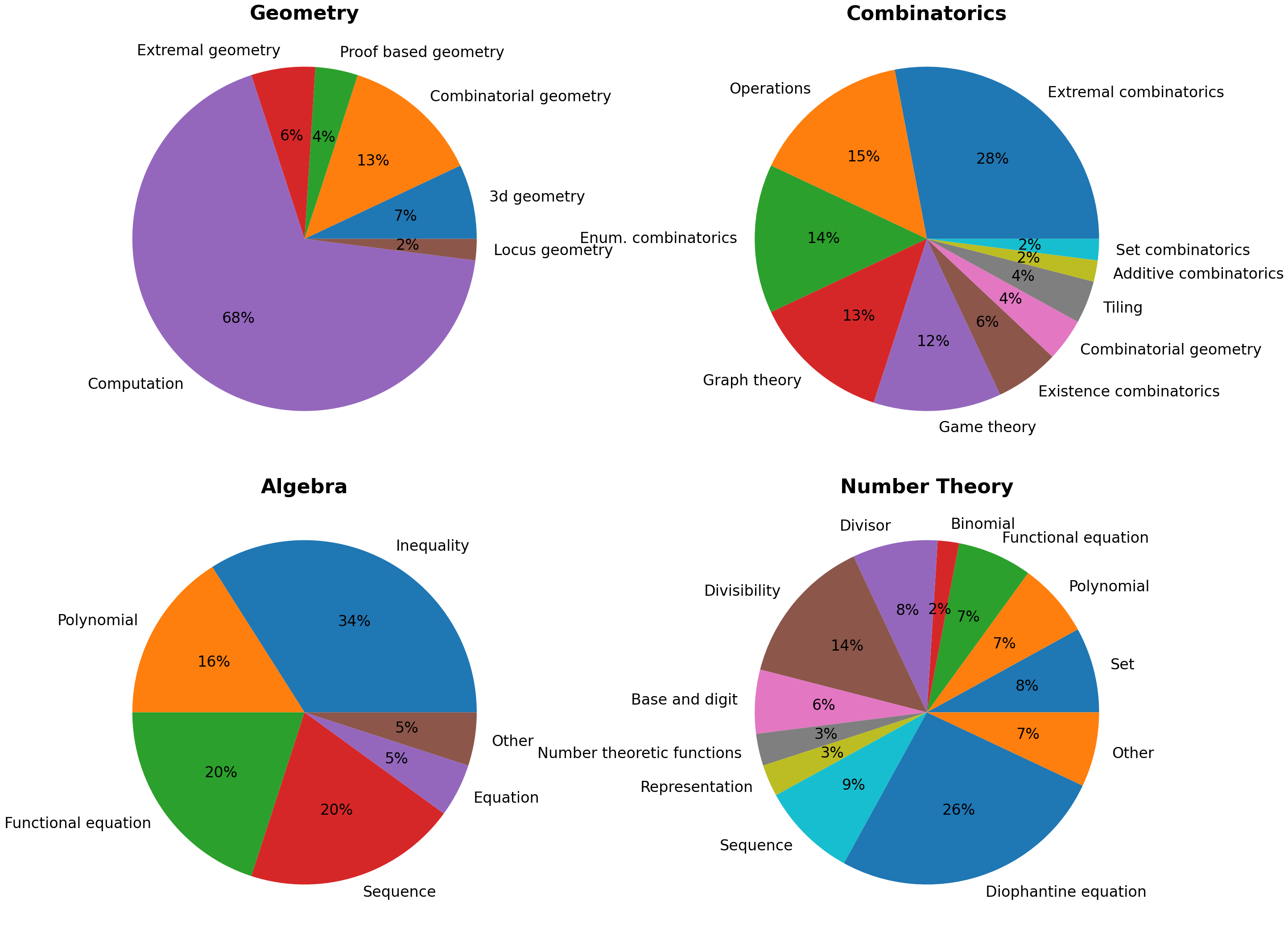
Topic distribution by category in IMO-AnswerBench. Number Theory and Combinatorics have the most topics which reflect the broad knowledge required to solve these problems while Geometry is mostly skewed towards angle and sidelength computation problems due to the nature of the short answer benchmark.
IMO-GradingBench
While IMO-ProofBench evaluates proof-writing abilities, it is equally important to assess models in terms of their ability to evaluate the correctness of given solutions. This capability is crucial for developing reliable automated grading systems and improving general mathematical reasoning. As part of our IMO effort, we have benchmarked extensively many internal models on the advanced set of IMO-Proof Bench using human evaluations. These human gradings led to the creation of IMO-GradingBench with 1000 examples, each containing a problem statement, a proposed solution, and its human-assigned grade (on a 0–7 scale). To reduce noise from fine-grained scoring, we frame the evaluation as a four-way classification by mapping the given IMO points to the labels (Correct, Almost, Partial, Incorrect) as detailed below.
| Category | IMO Points | Solution quality |
|---|---|---|
| Correct | 7 | Fully correct, rigorous, and complete |
| Almost | 6 | Almost correct, minor errors |
| Partial | 1 | Mostly incorrect, some relevant results |
| Incorrect | 0 | Completely incorrect or irrelevant. |
Our simplified IMO ratings.
To ensure a robust evaluation, the dataset has been balanced with a roughly equal number of examples per category. When problems are grouped by their IMO difficulties, a clear trend emerges. The proportion of correct and almost solutions decreases as the intended difficulty moves from IMO-easy to IMO-hard, while the proportion of incorrect and partial solutions increases. This confirms that the grading distribution of IMO-GradingBench aligns with its assigned difficulty levels.
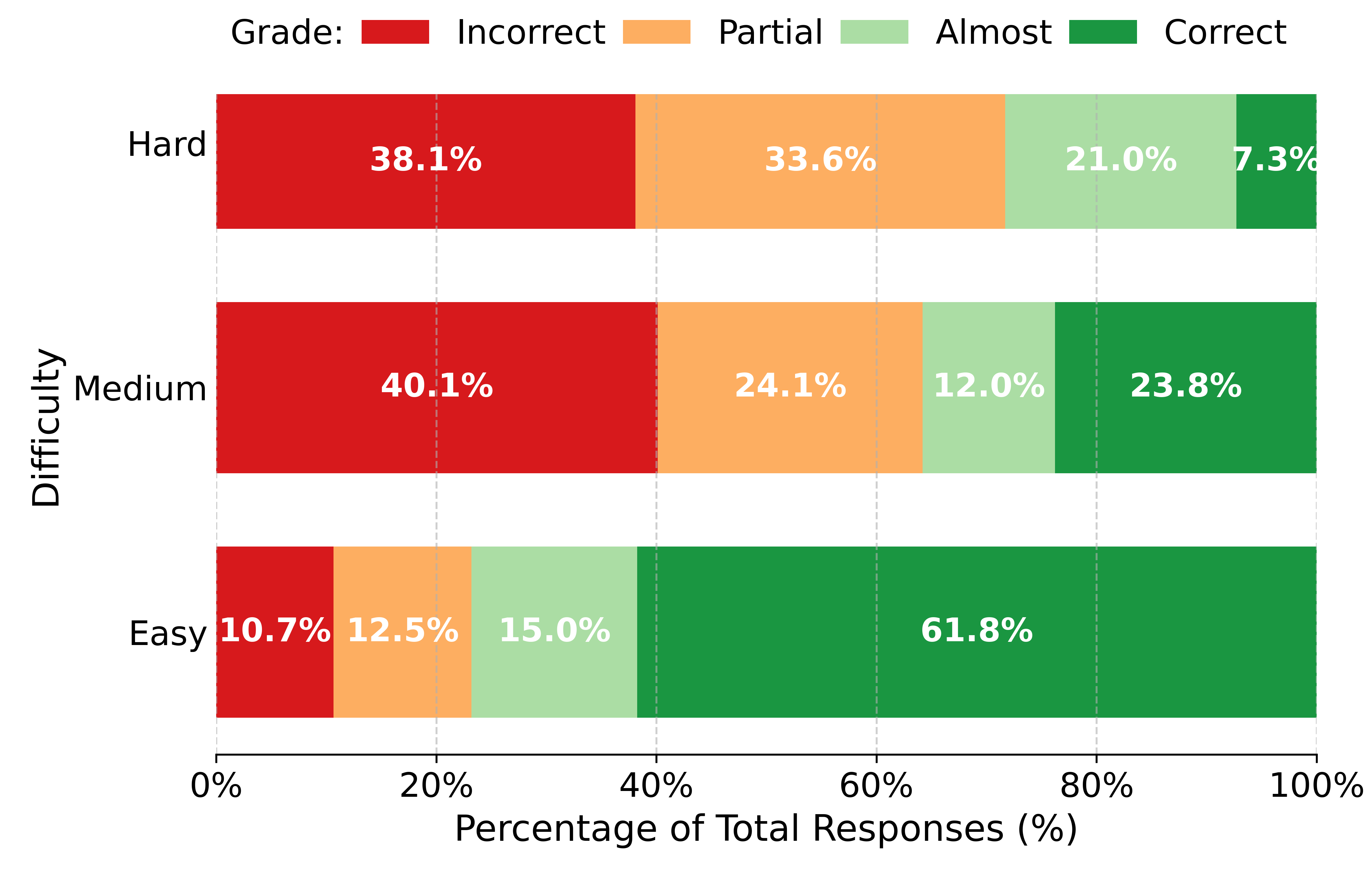
Grade distribution for solutions in IMO-GradingBench by difficulty levels (IMO-Hard, IMO-Medium, IMO-Easy).
For further details on these benchmarks and results, check out our IMO-Bench paper!
Citing this work
@inproceedings{luong-etal-2025-towards,
title = "Towards Robust Mathematical Reasoning",
author = {Thang Luong and Dawsen Hwang and Hoang H. Nguyen and Golnaz Ghiasi and Yuri Chervonyi and Insuk Seo and Junsu Kim and Garrett Bingham and Jonathan Lee and Swaroop Mishra and Alex Zhai and Clara Huiyi Hu and Henryk Michalewski and Jimin Kim and Jeonghyun Ahn and Junhwi Bae and Xingyou Song and Trieu H. Trinh and Quoc V. Le and Junehyuk Jung},
booktitle = "Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing",
year = "2025",
url = "https://aclanthology.org/2025.emnlp-main.1794/",
}